 Andy McDonald
Andy McDonald


When planning and building machine learning models, a question often asked is, “What features should I use as input to my model?”.
Often, it requires domain expertise to understand the theory behind the input data, how it was acquired and how it all relates to each other. However, there are cases where underlying patterns in the data may not be obvious to the interpreter, or the interpreter is relatively inexperienced with the data and, therefore, lacks some of the essential domain knowledge.
This article will delve into “feature selection”, a method that plays a significant role in assisting with input data selection. We will explore what feature selection is, the different methods of feature selection, and how the different methods can impact the final prediction result from a machine learning algorithm.
What is Feature Selection?
In data science and machine learning, a feature often refers to a single measurable property of the data set being investigated, such as a column within a tabular data set. Within the petrophysics domain, this translates to individual logging measurements such as bulk density (RHOB), neutron porosity (NPHI), gamma ray (GR) or any interpreted curve, such as porosity (PHIE) or clay volume (VCL).
When building machine learning models, the quality and relevance of the input data are essential to the success of the prediction results from the selected model. If poor quality data or incorrectly selected data is used, it could result in reduced precision of the chosen algorithm or erroneous predictions. This can have knock on consequences down the analysis pipeline.
As Petrophysicists, we know how the measurements are taken, and how they can be impacted by borehole conditions. This allows us better insights into what logging curves may be appropriate for the prediction of permeability or facies. However, there are cases where the relationships may not be obvious, and identifying the right input curves can become challenging.
Feature selection, a common technique within the machine learning workflow, helps select a subset of features or input curves from your dataset that are most influential and relevant to your chosen target feature you are trying to predict.
As seen in the generalised Machine Learning workflow below, the Feature Selection stage happens after the well log data has been quality checked, but prior to splitting the data into training and validation data sets. This allows you to get an understanding of the data prior to carrying out any modelling.
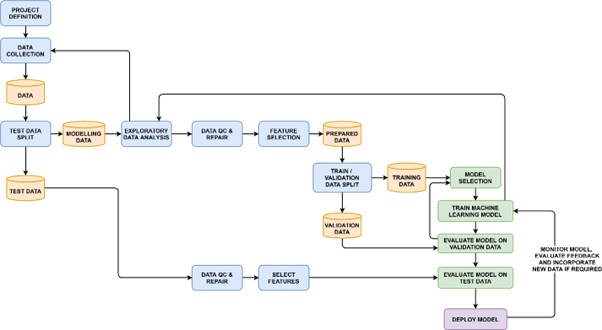
General Machine Learning workflow showing the various stages and processes when building, training and running Machine Learning models. Source: McDonald, A (2021)
Benefits of Applying Feature Selection to Machine Learning in Petrophysics
Not only does feature selection aid in selecting the most appropriate and relevant features to use in your chosen algorithm, it also has several other benefits.
The most important benefits include:
Improving training times of algorithms: With less input data to our models, the training of algorithms will become faster and use up less computer resources.
Improving model interpretability: With fewer features in the model it can make it easier to understand and explain how the selected machine learning model reached its conclusion.
Reducing the likelihood of overfitting: When noise and / or irrelevant features are included within a model, there is an increased likelihood of the model memorising the training data and not generalising well to new and unseen data. Therefore , by focusing on the most relevant features we can reduce the amount of noise and misleading data.
Improving prediction accuracy: It is a common misconception that feeding more data into a machine learning model will make it perform better. In actual fact, it can be detrimental to the accuracy of the prediction as redundant and irrelevant features can confuse the model.

Feature Selection Methods
There are numerous feature selection algorithms available and they can be broadly grouped into three categories:
Filter Methods are used to select subsets of the data and are independent of the chosen machine learning algorithms. This helps to reduce any bias that may be introduced by them. These methods are fast and rely on statistical tests (e.g. Pearson’s Correlation, Mutual Information, Information Gain) in relation to the target feature. The highest-ranked features, based on a threshold set by the interpreter, are carried forward to the modelling stages.
Wrapper Methods are a set of algorithms that are used to subset the input features through an iterative process. As a result, these algorithms can be very greedy in terms of computational time, however, they can lead to better results compared to filter-based methods. Wrapper-based algorithms include Backward Feature Elimination.
Embedded Methods work by training a machine learning model and then deriving the relative importance of each of the features relative to the prediction result.
Feature Selection in Action: An Example Using Well Log Measurements
To illustrate the process of feature selection using a single regression-based machine learning model and a wrapper type method, we can start with a list of 14 well log measurements. If we were to pass all of these into the model, we end up with a large scatter of points for our prediction and poor regression metrics. Essentially, we have too much noise or irrelevant features.
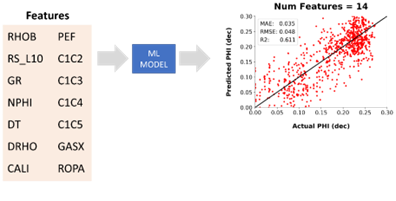 The start of feature selection process. Comparing the prediction output compared to the actual measurement when all input curves are included. Image from McDonald, A (2021)
The start of feature selection process. Comparing the prediction output compared to the actual measurement when all input curves are included. Image from McDonald, A (2021)
As the feature selection algorithm and modelling process is repeated, we end up knocking out several input curves. This results in a marginal improvement in the output and the metrics.
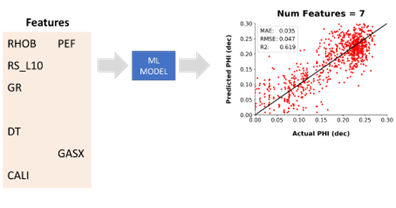
After a few iterations of the feature selection algorithm, the data is subsetted and the prediction result has slightly improved. Image from McDonald, A (2021)
The results and the input curves are re-assessed, and after a few more iterations, we end up with just three input curves. Bulk Density (RHOB), Acoustic Compressional Slowness (DTC) and Total Gas (GASX).
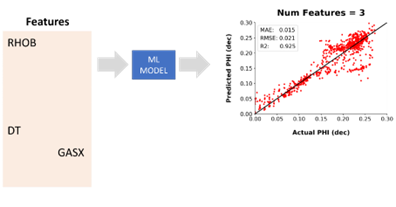
On the final iteration of the feature selection process, the prediction result improves significantly, with higher regression metrics and a better comparison to the actual data. Image from McDonald, A (2021)
The metrics have improved significantly from the first pass, and the first is much better in the lower porosity range. However, there is still scatter in the higher porosity intervals, which could warrant further investigation and modification to the machine learning model that was used.
Automated Feature Selection in IP with Experienced Eye
Creating, building and experimenting with machine learning models can be a tedious and time-consuming process, especially if we wanted to try out various combinations of input curves and models.
As an example, if we wanted to test different combinations of three to eight input curves, three feature selection models and three machine learning models we could end up with 54 different combinations. Carrying out this process manually could take several hours or even days. Automating this process and testing these different combinations can reduce this time to minutes.
This is what we have achieved with IP’s new Experienced Eye (EE) module for Feature and Model Selection and its adds a significant degree of automation to the Machine Learning bundle.
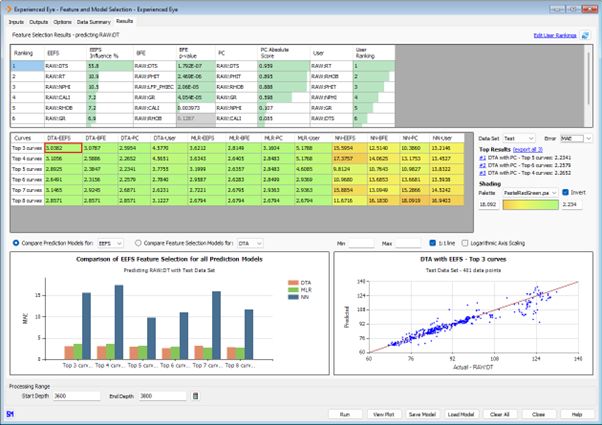
Automated Feature Selection and Machine Learning Model Selection with IP’s new Experienced Eye module.
The new module provides you with the options to use three different feature selection methods: Backward Feature Elimination, Pearson’s Correlation and a new proprietary method derived from Domain Transfer Analysis called Experienced Eye Feature Selection. Additionally, to test your domain expertise against the machine, it also allows you to pass in your own order for the input curves.
Following the feature selection stage, the top three to top eight ranked input curves from each Feature Selection method and the User Defined Order are then passed into IP’s Machine Learning Models: Multiple Linear Regression, Domain Transfer Analysis and Neural Networks. The performance of each of these models is then assessed and presented in a single, easy to understand interface. From here, you can select your best performing models and export them directly to your selected Machine Learning model and run it across multiple wells within your database.
To help you identify the best performing models, all of the data from your chosen well is split up into a training data set, which is used to build the models, and a testing data set, which is used to evaluate the model’s performance on unseen data – in other words how well that model generalises to new data.
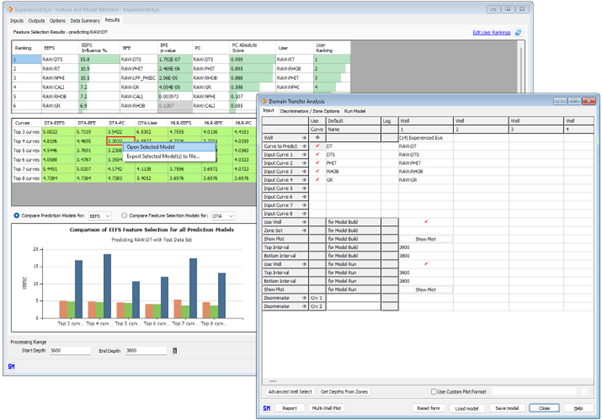
Easily export best performing Feature Selection and Machine Learning Algorithm combinations to IP’s Curve Prediction and Machine Learning modules.
Conclusion
Feature Selection is a well-used methodology within the machine learning domain. It greatly speeds up the process of identifying relevant features in relation to a prediction target, especially when you have an abundance of input curves. However, as with any tool it is essential to always check the results and utilise domain knowledge to assess the predictions results rather than using them blindly.
The adoption and usage of machine learning in petrophysics is reliant on the successful integration of domain knowledge with cutting edge algorithms.
The introduction of Experienced Eye within IP 5.3 illustrates that integration. The module provides you with the opportunity to streamline and automate your curve prediction process, whilst bridging the gap between data-driven results and domain expertise. This helps speed up the process of building machine learning models, and reduces the need for repetitive trial and error. Feature selection methods additionally demystify the decision making process used by machine learning algorithms and help you understand how prediction models have arrived at their conclusion by showing how relevant each input curve is to your target curve.
IP 5.3 is due for release in October 2023, if you are interested in learning more about Experienced Eye or machine learning workflows in IP, please feel free to get in touch and we would love to chat with you about your needs.
References
Arkalgud, R., McDonald, A. and Brackenridge, R., 2021. Automated Selection of Inputs for Log Prediction Models Using a New Feature Selection Method. SPWLA 62nd Annual Logging Symposium. [online] Virtual Event, May. Available at: https://doi.org/10.30632/SPWLA-2021-0091
Arkalgud, R., McDonald, A. and Brackenridge, R., 2020. Automated Selection of Inputs for Log Prediction Models Using Domain Transfer Analysis DTA Derivative. Abu Dhabi International Petroleum Exhibition & Conference. [online] Abu Dhabi, UAE, November. Available at: https://doi.org/10.2118/203094-MS
Arkalgud, R., McDonald, A. and Brackenridge, R., 2021. Automated Selection of Inputs for Log Prediction Models Using a New Feature Selection Method. SPWLA 62nd Annual Logging Symposium. [online] Virtual Event, May. Available at: https://doi.org/10.30632/SPWLA-2021-0091
Arkalgud, R., McDonald, A. and Crombie, D., 2019. Domain Transfer Analysis – A Robust New Method for Petrophysical Analysis. SPWLA 60th Annual Logging Symposium. [online] The Woodlands, Texas, USA, June. Available at: https://doi.org/10.30632/T60ALS-2019_HHHH
McDonald, A., 2021. Data Quality Considerations for Petrophysical Machine-Learning Models. Petrophysics, [online] 62, pp.585-613. Available at: https://doi.org/10.30632/PJV62N6-2021a1


Machine Learning for Petrophysics: Data Quality & Workflows
When developing petrophysical machine learning models, it is essential to ensure that input data is of high quality, trustworthy and reliable. Data...