 Andy McDonald
Andy McDonald
Well Log Data Management Software
Well log data is a key source for petrophysical analysis and machine learning models, however, it can be affected by a range of issues including...

When developing petrophysical machine learning models, it is essential to ensure that input data is of high quality, trustworthy and reliable. Data quality shouldn’t be viewed as just a technical detail, but rather a foundational step in the process of ensuring petrophysical data driven prediction models are fit for purpose.
Interest in machine learning and AI has increased significantly within the petrophysics domain over recent years.
Applications range from predicting missing well logging curves and reservoir properties to improving pore pressure predictions. However, ensuring that decisions based upon these models are robust and reliable depends on good-quality input data.
If poor-quality data is used in machine learning models for petrophysics, it can lead to unreliable predictions, misleading models, and hours of troubleshooting. This can in turn impact key business decisions and future geological interpretations. In other words, if we feed rubbish into our models, then we will get rubbish results out.
In this article, we will explore data quality for petrophysical machine learning workflows in more depth.
Data quality refers to how well the data serves its intended purpose. In other words, “is the data I am using in my model suitable for the specific objectives of my project?”. It is not just about having correct data, it is about having data that is trustworthy, relevant, valid and complete.
By using good-quality data, we can help our machine learning models understand patterns in the data that reflect the real subsurface, rather than from noise or inconsistencies.
Ensuring good quality data should not be seen as a technical one-off task or a tick-box exercise; it should form the foundation of the interpretation and modelling workflow. Without it, even the most advanced algorithms can produce misleading or unstable results.
The impact of using poor-quality data has far-reaching consequences:
When working with petrophysical datasets and machine learning algorithms, it is important to note that many of the algorithms and methodologies used can be very sensitive to the data that is passed into them.
If poor quality data is fed in, it can lead to poor quality results, including:
To ensure that the term Data Quality is qualitative, a number of key properties have been discussed in the literature. Most of the research discussing data quality is in alignment with the six key dimensions set out by the DAMA UK Working group (2013), which are as follows:
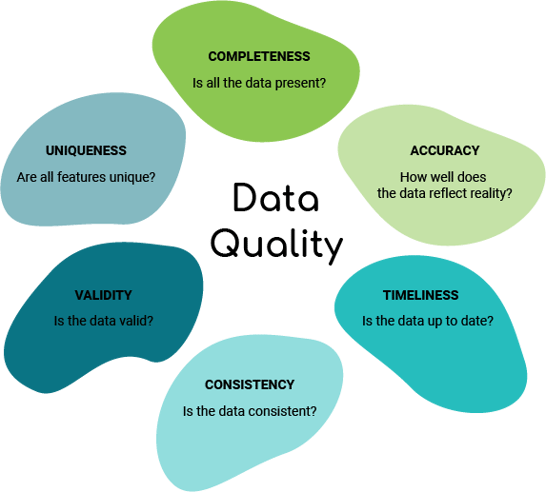
The data should accurately reflect the reality of the object being described. In the case of well logs, the object of interest is the subsurface: Are we accurately capturing the geological variation within the logging tool measurements?
Data should be as complete as possible for the intended task. This dimension provides a measure of the presence of non-null values in terms of percentage. This will range between 0% (no values present – all nulls) and 100% (all values present – no nulls).
If data are missing, they should be examined to determine the cause before applying any correction techniques. Data could be missing for a number of reasons, including logging tool issues, missing by choice, and the logging technology not being present in wells logged decades ago.
Data should be consistent when compared against itself across different storage locations, software packages, and file formats. For example, if a density log on a log plot in a DLIS file and a LAS file are the same, then that is consistency.
When working with data, we should use the most up-to-date version possible. This will ensure that decisions are based on the latest data.
When working with well log data, we also have to consider the vintage of that data. For example neutron porosity tools in the 1960s are different to those used today, and would require different corrections or conversions.
Finally, we need to consider temporal changes in the borehole between logging passes, for example, if the well has been left for several days or weeks, then when it is logged again there may be visible signs of mud filtrate invasion.
The acquired data should fit within predefined limits and expectations and be of the correct type. For example, if a bulk density curve should typically have values between 1.5 and 3 g/cc, but the acquired data contains values of 7 or 42, then those values would fall outwith those limits and would be considered invalid.
Entities within a data set should not exist more than once. It is common when working in databases for there to be duplication of curves. This duplication could come from different logging passes, repeat sections and different contractors and result in multiple “GR” or “DT” curves for example.
Well logging data can be affected by multiple data quality issues caused by a variety of reasons. The following are some (but not all) examples of data quality issues experienced within well log and petrophysical datasets:
Missing data is a common problem and occur when no data values are stored for a well-log measurement. This reduces the completeness of the data, which can impact how it is used and what can be inferred from the data.
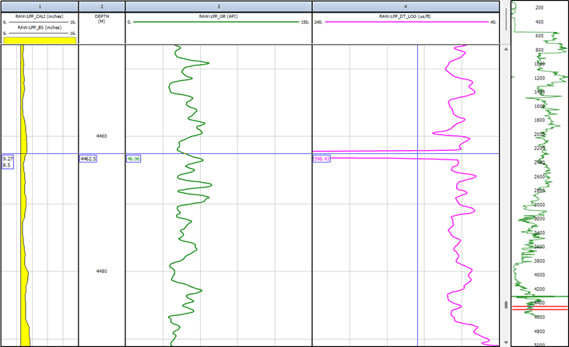
In the example below, we can see that the Neutron Porosity curve is missing some data. This has been flagged by the IP Log QC Module.
.png?width=567&height=393&name=image%20(5).png)
Outliers are anomalous data points that do not fit within the normal or expected statistical distribution of the data set. Outliers can occur due to a variety of reasons, including measurement errors, poor data collection techniques, and unexpected events.
In the example below, an outlier can be seen within the Sonic Slowness curve (DT), which reads values just below 600 us/ft, which is far beyond the expected range for this curve. This spike does not tie in with other curves, such as the caliper or gamma ray. This may point to a tool or processing error.
However, outliers are not always an indicator of poor quality data; they could be a result of unusual or unexpected geology. As a result, it is not best practice to blindly remove them from the dataset. Instead, these outliers should be investigated to determine why they are classed as outliers.
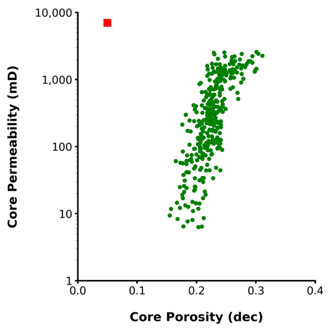
In the example below, we have a crossplot of core porosity vs core permeability. Nearly all data points are together in a cluster, with the exception of 1 data point which shows a low porosity, but a high permeability. This could be a result of a fractured core plug sample.
Depth is a critical measurement and is required for the successful development of an asset. All logging measurements are tied to depth, and subsequently, all decisions will be based upon depth. For example, having an accurate depth allows the successful selection of perforation intervals and the setting of packers at the correct depth within the well.
Ensuring that multiple logging measurements are at a consistent depth is essential to any petrophysical interpretation. However, there can be numerous issues that affect the accuracy of the depth measurements, including pipe stretch, inconsistent depth calibrations, and stick and pull.
When logging is carried out over cased hole intervals, the measurements can be severely impacted.
For example,
In some cases, the petrophysicist or data preparer may have to remove all or part of this data to clean up the logs. If this is done, it needs to be well documented otherwise it could lead to being interpreted as missing data.
Logging measurements are acquired in a hostile and difficult environment, where temperatures and pressures are often high.
During Logging While Drilling (LWD), there is the added punishment from drilling vibrations and other related processes. This can impact the tool performance ranging from intermittent sensor measurements to complete tool failure affecting entire logging measurements. Both of which can lead to missing data.
If a data set has previously been worked on, then it is possible gaps may have been introduced by the previous interpreter due to the issues detailed above. This is sometimes done to create a clean working data set, and is something that should be well documented and obvious to future interpreters.
The way data has been stored and processed over the decades has changed significantly since well logging began. Data can easily be mislabeled or misplaced or even lost when data is transferred or the data system changes.
Additionally, when databases are worked on, the data can easily be duplicated or overwritten, which can in turn lead to data loss if not properly documented.
Ensuring that we have good-quality data is not just a technical task or tick-box exercise; it is essential for making confident and effective business decisions. In petrophysics, having good-quality and trustworthy data can improve model reliability, reduce uncertainty in reservoir estimates, and reduce time spent troubleshooting models, which can lead to increased operational efficiency.
Well log data can be impacted by a variety of issues from tool sensor issues resulting in missing data to outliers caused by borehole environmental conditions. However, with proper QC processes in place, you can significantly reduce these risks within your petrophysical machine learning models and interpretations by using reliable, consistent and trustworthy data.
By ensuring high quality input data, you not only improve model performance and reduce false positives, but also gain greater confidence in your results.
McDonald, A., 2021. Data Quality Considerations for Petrophysical Machine-Learning Models. Petrophysics, [online] 62, pp.585-613. Available at: https://onepetro.org/petrophysics/article-abstract/62/06/585/473276/Data-Quality-Considerations-for-Petrophysical
McDonald, A., 2022. Impact of Missing Data on Petrophysical Regression-Based Machine Learning Model Performance. SPWLA 63rd Annual Logging Symposium, June 2022. Available at: https://onepetro.org/SPWLAALS/proceedings-abstract/SPWLA22/4-SPWLA22/D041S016R004/487867

Well log data is a key source for petrophysical analysis and machine learning models, however, it can be affected by a range of issues including...

Nuclear Magnetic Resonance (NMR) logging has come a long way since its inception as a permeability tool, when researchers in the 1960s discovered the...
